January 18, 2021 by Sql Times
Interesting one today:
Occasionally, when we restore databases from backups, we need to fix orphan users. Recently, a few years ago, we discussed about fixing orphan users using script. Here we’ll look at a scenario, where the regular orphan users script will not work.
Error Message:
Msg 15600, Level 15, State 1, Procedure sp_change_users_login, Line 214 [Batch Start Line 61]
An invalid parameter or option was specified for procedure ‘sys.sp_change_users_login’.
The script “EXEC sp_change_users_login 'Auto_Fix', 'user'” only works for Sql Authentication based logins and not for Windows-level principals or non-login based users. See MSDN article for more details.
A user without login would look like this, in SSMS:

Sql Users Without Login
In such scenarios,
- sp_change_users_login cannot be used to map database users to Windows-level principals, certificates, or asymmetric keys.
- sp_change_users_login cannot be used with a SQL Server login created from a Windows principal or with a user created by using CREATE USER WITHOUT LOGIN.
Hope this helps,
Posted in Cool Script, DBA, DBA Interview, Error Messages, Move databases, Security, Sql Server 2008, Sql Server 2008 R2, Sql Server 2012, Sql Server 2014, Sql Server 2016, Technical Documentation, Tips and Techniques, TSQL | Tagged An invalid parameter or option was specified for procedure 'sys.sp_change_users_login', CREATE USER WITHOUT LOGIN, EXEC sp_change_users_login 'Auto_Fix' 'user', sp_change_users_login cannot be used with a SQL Server login created from a Windows principal, sql server fix orphan users | Leave a Comment »
January 13, 2021 by Sql Times
Interesting one today:
In our development environment, sometimes we run into this error that’s a bit nebulous.
Error Message:
SQLException for SQL []; SQL state [S0001]; error code [4502]; View or function has more
column names specified than columns defined.;
nested exception is com.microsoft.sqlserver.jdbc.SQLServerException:
View or function has more column names specified than columns defined.
Occasionally, we make changes to the tables schema and when you have Views that depend on these tables, they become stale. While the definition is still intact, the meta-data becomes stale, so they need to be refreshed.
This refresh uncovers if there are any conflicts between view definitions and the underlying tables.
--
-- Refresh View metadata
--
EXEC sp_refreshview 'dbo.View_SomeTable'
GO
Once the underlying conflicts are resolved, if any, the view will execute correctly from application. Just refreshing the meta-data helps sometimes.
Hope this helps,
Posted in Cool Script, DBA, DBA Interview, Error Messages, Move databases, Sql Server 2008, Sql Server 2008 R2, Sql Server 2012, Sql Server 2014, Sql Server 2016, Technical Documentation, Tips and Techniques, TSQL | Tagged EXEC sp_refreshview, view meta-data becomes stale, View or function has more column names specified than columns defined | Leave a Comment »
December 15, 2020 by Sql Times
Quick one today:
Sometimes we need to find out the last time a table was touched, either for INSERT/UPDATE or for READ. This is not a regular use case.
In any given second, a busy database processes thousands of transactions; so it a rare scenario where we’ll stop the activity to find the time when a table was touched.
While it is rare, the need arises, mostly in DEV & TEST environments, where we need to query the last time a table was updated.
The below T-SQL helps us uncover the details:
--
-- Create temporary table for the test
--
CREATE TABLE dbo.TempUpdate (ID INT, Place VARCHAR(20))
GO
--
-- Perform INSERT and check the timestamp
--
INSERT INTO dbo.TempUpdate (ID, Place) VALUES (1, 'Test')
GO
SELECT OBJECT_NAME(object_id), last_user_update, last_user_lookup, last_user_scan, last_user_seek
FROM sys.dm_db_index_usage_stats
WHERE database_id = 23
AND OBJECT_NAME(object_id) = 'TempUpdate'

INSERT Timestamp
--
-- Perform UPDATE and check the timestamp
--
UPDATE dbo.TempUpdate SET Place = 'Test2'
GO
SELECT OBJECT_NAME(object_id), last_user_update, last_user_lookup, last_user_scan, last_user_seek
FROM sys.dm_db_index_usage_stats
WHERE database_id = 23
AND OBJECT_NAME(object_id) = 'TempUpdate'
GO
--
-- Clean up
--
DROP TABLE dbo.TempUpdate
GO

Updated Timestamp
Side Note: As notice, table scan was performed while performing UPDATE
--
-- Clean up
--
DROP TABLE dbo.TempUpdate
GO
Hope this helps,
Posted in Cool Script, DBA, Sql Server 2008, Sql Server 2008 R2, Sql Server 2012, Sql Server 2014, Sql Server 2016, Technical Documentation, Tips and Techniques, TSQL | Tagged dm_db_index_usage_stats, sys.dm_db_index_usage_stats, table inserted timestamp, table update timestamp, the last time a time was modified, When was the last time a table was updated | Leave a Comment »
November 24, 2020 by Sql Times
Interesting one today:
Earlier this week, while playing one of our cloud database servers, ran into this confusing error.
Error Message:
A connection was successfully established with the server, but then an error occurred during the
login process. (provider: SSL Provider, error: 0 - The certificate chain was issued by an authority
that is not trusted.) (Microsoft SQL Server, Error: -2146893019)
The certificate chain was issued by an authority that is not trusted

Connection Certificate Error
Details:
This is one of those Sql Server errors that are clear and actionable. It clearly indicates that a connection to Sql Server was successfully established, but the encryption certificate (for secure communications) was the problem.
Seems like SSMS received the certificate from the server but it does not seem to be from one of the Trusted Certificate Authorities (CA) — hence the failure in going forward with maintaining the connection.
My guess is that this certificate is used both for identification (authentication) and encryption.
- You are who you say you are (for both parties)
- If I send you something, only you can decrypt it and vice versa
Usually these certificates are issued by CAs, Certificate Authorities, that verify you before giving you a public and private key. But Windows allows us to generate our own certificates for free, but these do not come with seal of approval from CAs.
In our case, its the latter. The certificate sent to SSMS was a generated one and not a CA issues certificate. Hence the error message.
Resolution:
Go to “Connect to Server” pop-up window >> Options >> Check “Trust server certificate“.
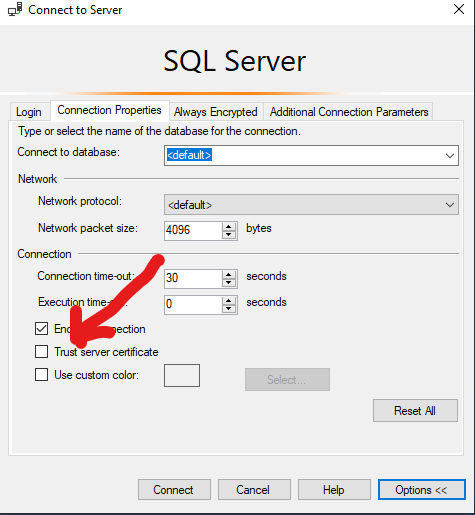
Trust Connection Certificate
Once selected, SSMS will accept the remote certificate and complete connection.
Hope this helps,
Posted in DBA, Error Messages, Operating System, Sql Server 2008, Sql Server 2008 R2, Sql Server 2012, Sql Server 2014, Sql Server 2016, Technical Documentation, Tips and Techniques, Weird Anamoly | Tagged A connection was successfully established with the server but then an error occurred during the login process, A connection was successfully established with the server but then an error occurred during the login process. (provider: SSL Provider error: 0 - The certificate chain was issued by an authority that , Certificate Authorities, Connect to Server, Microsoft SQL Server Error: -2146893019, provider: SSL Provider error: 0 - The certificate chain was issued by an authority that is not trusted., Sql Server Connection Failure, The certificate chain was issued by an authority that is not trusted, Trust server certificate | Leave a Comment »
November 23, 2020 by Sql Times
Interesting one today:
A while ago, we looked at the lock escalation patterns within Sql Server. Today, we’ll cover a couple of trace flags that impact that lock escalation. Thanks to my friend Bob for this idea.
- Trace Flag 1211
- Trace Flag 1224
Trace Flag 1211:
In short, this flag prevents Sql Server from escalating locks under any circumstances.
Within Sql Server, as we saw in the previous article, Sql Server prefers to carry out the work with least number of locks at the least level of locks. If work could be carried out with Row Locks, then Sql Server would issue necessary row locks on the records and carry out the task. When the number of row locks goes beyond a threshold, then it escalates to page-lock or table lock.
This default behavior could be altered with the trace flag 1211. When we enable this trace flag, Sql Server will not escalate locks. If it has row locks, it will carry out the work with row-locks, even if more and more row locks are needed (and even if its efficient to carry out the operation with fewer page locks or a single table lock).
More locks causes more memory pressure — as each lock takes certain amount of memory space. So even under memory pressure, it will work within current lock levels. If and when it runs out of memory, it issue an error (1204).
This is a powerful trace flag, so its better to not use it. There is a better alternative. Trace Flag 1224.
Trace Flag 1224:
In short, Sql Server prefers to complete the operation under current lock-level, but if that incurs memory pressure, then it escalates locks. This is a much better way to handle lock escalation than trace flag 1211.
Note: If both the flags are enabled, then trace flag 1211 takes precedence over 1224. So there will not be any lock escalation even under memory pressure.
Note: Use this script to enable or disable a trace flag or to check trace flags status.
Hat tip to Bob for the idea.
Hope this helps,
Posted in DBA, DBA Interview, Error Messages, Performance Improvement, Sql Server 2008, Sql Server 2008 R2, Sql Server 2012, Sql Server 2014, Sql Server 2016, Technical Documentation, Tips and Techniques, TSQL | Tagged page lock, row lock, Sql Server Error 1204, Sql Server lock escalation, Sql Server Trace Flags 1211 and 1224, table lock, Trace Flag 1211, Trace Flag 1224 | Leave a Comment »
November 19, 2020 by Sql Times
Quick one today:
Recently, we saw a time-saving technique in starting job using T-sql query.
Today, we’ll look at another one. This comes in handy when dealing with multiple jobs — where handling them is more efficient using T-SQL than UI. Even during deployments, where we need to disable jobs at the beginning of the deployment and then enable them at the end.
--
-- Enable a Sql Agent Job
--
USE msdb
GO
EXEC dbo.sp_update_job @job_name = N'SomeJobName'
, @enabled = 1
GO
This is simple and elegant way to enable/disable one or many jobs at the same time, making interaction with SQL Server more efficient. Just query job names from
--
-- Get list of job names
--
SELECT * FROM msdb..sysjobs
GO
Hope this helps,
Posted in Cool Script, DBA, DBA Interview, Sql Server 2008, Sql Server 2008 R2, Sql Server 2012, Sql Server 2014, Sql Server 2016, Technical Documentation, Tips and Techniques, TSQL | Tagged disable sql agent job, enable sql agent job, msdb, msdb..sysjobs, sp_update_job, Sql Server : Enable a Sql Agent Job using T-SQL query, sql server jobs, sysjobs | Leave a Comment »
November 8, 2020 by Sql Times
Quick one today:
Occasionally, we need to change the password of a login within SQL Server. Following T-SQL template is handy query to carry out that operation.
--
-- Change login password using T-SQL
--
ALTER LOGIN [Login]
WITH PASSWORD = 'new password'
GO
Hope this helps,
Posted in Cool Script, DBA, Sql Server 2008, Sql Server 2008 R2, Sql Server 2012, Sql Server 2014, Sql Server 2016, Technical Documentation, Tips and Techniques, TSQL | Tagged ALTER LOGIN WITH PASSWORD, Sql Server : Change Login Password using TSQL Query | Leave a Comment »
November 4, 2020 by Sql Times
Interesting one today:
In our lab environment, while setting up replication on a few nodes, we ran into this interesting error message.
Error:
Msg 14100, Level 16, State 1, Procedure sp_MSrepl_addsubscription, Line 15
Specify all articles when subscribing to a publication using concurrent snapshot processing.
At first glance, it did not make much sense — as we did not make any changes to the code. But upon further digging, it became obvious the minor change that was made.
@sync_method parameters.
The section where we define the publication, looks like this:

Replication Add Publication
While defining the publication, along with all other parameters, we also mention the way in which the articles & data from Publisher is sent to each Subscriber.
@sync_method defines, which approach to take.
The associated ‘add_subscription’ (which threw the error) looks like this:

Replication Add Subscription
Solution:
When a Publication is defined with @sync_method as ‘concurrent‘, then it creates all articles/tables as one chunk of data (not as individual tables) in native mode. So we need to be sure to define @article parameter in ‘sp_addSubscription‘ with ‘all’ as value (and not individual table names) — since the articles are not available individually.

Replication Add Subscription
Viola !! Now the add subscription works !!
Side note:
If you want to add individual tables/articles in the ‘sp_addsubscription‘, then you want to consider using ‘native‘ for @sync_method.

Replication Add Publication
Replication Add Subscription
Hope this helps,
Posted in Cool Script, DBA, Replication, Sql Server 2008, Sql Server 2008 R2, Sql Server 2012, Sql Server 2014, Sql Server 2016, Technical Documentation, Tips and Techniques, TSQL, Weird Anamoly | Tagged @article = N'all', @sync_method = N'concurrent', @sync_method = N'native', Msg 14100 Level 16 State 1 Procedure sp_MSrepl_addsubscription Line 15, Msg 14100 Level 16 State 1 Procedure sp_MSrepl_addsubscription Line 15 Specify all articles when subscribing to a publication using concurrent snapshot processing., Specify all articles when subscribing to a publication using concurrent snapshot processing., sp_addpublication, sp_addsubscription, sp_MSrepl_addsubscription, Sql Server Replication Error | Leave a Comment »
November 1, 2020 by Sql Times
Interesting one today:
On a lab machine, when CHECKDB was executed, this seemingly tricky error popped up. This was a lab machine, and there was no traffic or any one connected to it.
Code that we ran:
--
-- CHECKDB error
--
DBCC CHECKDB ('DB')
WITH ALL_ERRORMSGS
, EXTENDED_LOGICAL_CHECKS
, TABLOCK
GO
Error Message:
Msg 5030, Level 16, State 12, Line 1 The database could not be exclusively locked to
perform the operation.
Msg 7926, Level 16, State 1, Line 1
Check statement aborted. The database could not be checked as a database snapshot
could not be created and the database or table could not be locked.
See Books Online for details of when this behavior is expected and what workarounds
exist. Also see previous errors for more details.
After checking that there was no traffic or any connections to the database, I re-ran the same CHECKDB a few more times and still ran into the same error.
Reading this MSDB article, some ideas came to mind. The two conditions mentioned in the article are not the root of the problem.
- At least one other connection is using the database against which you run the DBCC CHECK command.
- The database contains at least one file group that is marked as read-only.
Once the TABLOCK is removed, the command worked.
DBCC CHECKDB ('DB')
WITH ALL_ERRORMSGS
, EXTENDED_LOGICAL_CHECKS
GO
Posted in Cool Script, DBA, Error Messages, Sql Server 2008, Sql Server 2008 R2, Sql Server 2012, Sql Server 2014, Sql Server 2016, Technical Documentation, Tips and Techniques, TSQL, Weird Anamoly | Tagged At least one other connection is using the database against which you run the DBCC CHECK command, CHECKDB, DBCC CHECKDB Error Msg 5030 Level 16 State 12 Line 1 The database could not be exclusively locked to perform the operation., Msg 5030 Level 16 State 12 Line 1 The database could not be exclusively locked to perform the operation., Msg 7926 Level 16 State 1 Line 1 Check statement aborted. The database could not be checked as a database snapshot could not be created and the database or table could not be locked. See Books Online , SQL SERVER CHECKDB, The database contains at least one file group that is marked as read-only | Leave a Comment »
October 28, 2020 by Sql Times
Interesting one today:
When we run a query with SET STATISTICS TIME ON, we see CPU Time and Elapsed Time statistics for a query. What is the difference?

SET STATISTICS ON
CPU Time is amount of CPU cycles (in time) spent by the workload thread on a particular processor/CPU. This is not an indication of the duration since the query began running on that CPU (there are some nuances — we’ll cover below)
Elapsed Time is the total duration of that thread, the time it took from start to end.
Simple Example:
Let’s say there is a workload thread for a simple query. The query runs for a bit (let’s say 2 seconds) and gets put on hold for a bit (let’s say 5 seconds), and then runs again (let’s say for 1 second) all the way to completion. The time the thread actually spent on CPU is counted towards CPU time (the two times, 2 & 1 seconds — 3 seconds total). Elapsed time is the total duration from when the query was issued to be executed to the time the result was generated — total 8 seconds.
Parallel Processing:
Let’s say there are 4 thread carrying out the workload of a query. Each run on a processor for 1 second and complete all the work in one shot.
Total CPU Time = 4 * 1 = 4 seconds (4 CPU’s with 1 second each)
Elapsed Time = 1 second (from start to finish)
Summary
CPU Time and Elapsed Time measure different time metrics for the same query. One measure the CPU cycles spent (in time) and the other measures the duration. The difference is important in figuring out what problem we are trying to solve.
- If a query has high Elapsed Time, but low CPU Time, that means, there is some CPU contention or other resource contention (waiting for all resources to be available before the query could be given a CPU).
- We want to look for ways to optimize the the way query is written — is it requesting for more resources (rows) than it needs. End user will feel the pain in waiting — if this happens to majority of the queries.
- Adding to this, if the CPUs are all busy all the time, that definitely means we need bigger CPUs for the workload or optimized queries.
- Conversely, if the CPU’s are not too busy at this time, that means, the thread is just waiting for other resources (concurrency — locked tables) to be released for this query to progress. Optimize the queries.
- If CPU Time is higher than Elapsed Time, then there is good amount of parallelism in play.
- As long as the CPUs are optimally utilized, this is not a problem, but if you notice more than 80% utilization all the time (the threshold is even lower if they are virtual CPUs), then we need to add extra CPUs to alleviate the situation.
- This may not be a problem right now, but it will evolve into a problem soon. One extra long query will snowball everything into high delays — to the point where a user will notice the delays.
Hope this helps,
Posted in DBA, DBA Interview, Operating System, Sql Server 2008, Sql Server 2008 R2, Sql Server 2012, Sql Server 2014, Sql Server 2016, Technical Documentation, Tips and Techniques, TSQL, Weird Anamoly | Tagged CPU Time is amount of CPU cycles (in time) spent by the workload thread on a particular processor/CPU. This is not an indication of the duration since the query began running on that CPU, SET STATISTICS TIME ON, Sql Server : CPU TIME vs. Elapsed Time, Sql Server CPU TIME, Sql Server Elapsed Time | Leave a Comment »
Older Posts »
