Interesting topic today.
When you create UNIQUE constraint on a table, to prevent any duplicate records, there are a couple of options.
- Create UNIQUE INDEX with necessary columns
- CREATE UNIQUE CONSTRAINT, if it is a single column
In this process, there are a couple of nuances that change this behavior; In particular, the focus is on how IGNORE_DUP_KEY flag affects the behavior. Lets look in detail with and without a UNIQUE constraint.
In this post, the focus is on the affects of IGNORE_DUP_KEY flag on UNIQUE and non-UNIQUE indexes.
With UNIQUE Index
For the same table, lets create a regular index (non-UNIQUE) index with IGNORE_DUP_KEY setting and see how it behaves when a duplicate record is inserted.
--
-- Create a sample table
--
CREATE TABLE dbo.Test_IGNORE_DUP_KEY (
ID INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED
, Name VARCHAR(10) NOT NULL
, SSN VARCHAR(15) NOT NULL
)
GO
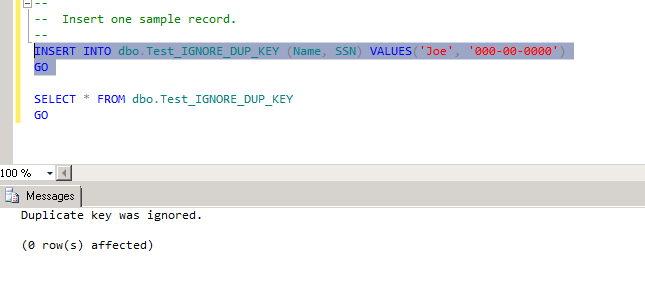
--
-- Insert one sample record.
--
INSERT INTO dbo.Test_IGNORE_DUP_KEY (Name, SSN)
VALUES('Joe', '000-00-0000')
GO
SELECT * FROM dbo.Test_IGNORE_DUP_KEY
GO
Lets see the result.

Sample table to test IGNORE_DUP_KEY
IGNORE_DUP_KEY = ON
With IGNORE_DUP_KEY = ON, when a duplicate record is inserted, the new duplicate record does not get inserted as expected, but it does not generate any errors. So, this flag, tells Sql Server to ignore any duplicate records.
--
-- Create UNIQUE index with "IGNORE_DUP_KEY = ON"
--
CREATE UNIQUE NONCLUSTERED INDEX UQ_Test_IGNORE_DUP_KEY_SSN
ON dbo.Test_IGNORE_DUP_KEY (SSN ASC)
WITH (IGNORE_DUP_KEY = ON)
GO
Now, when new duplicate record is inserted, the follow “informational message” is displayed. The duplicate record is not inserted into the table. When multiple duplicate records are inserted, all duplicate records are ignored, while non duplicate entries are successfully inserted.
Duplicate key was ignored.
(0 row(s) affected)

IGNORE_DUP_KEY : Informational Message
With IGNORE_DUP_KEY = OFF
--
-- Create UNIQUE index with "IGNORE_DUP_KEY = OFF"
--
CREATE UNIQUE NONCLUSTERED INDEX UQ_Test_IGNORE_DUP_KEY_SSN
ON dbo.Test_IGNORE_DUP_KEY (SSN ASC)
WITH (IGNORE_DUP_KEY = OFF)
GO
Upon INSERTing a new duplicate record, we get the following error message
Msg 2601, Level 14, State 1, Line 1
Cannot insert duplicate key row in object 'dbo.Test_IGNORE_DUP_KEY' with unique
index 'UQ_Test_IGNORE_DUP_KEY_SSN'. The duplicate key value is (000-00-0000).
The statement has been terminated.

IGNORE_DUP_KEY : Error Message
Without UNIQUE Index
Now lets check the same setting without a UNIQUE index or constraint on this column and measure the behavior.
IGNORE_DUP_KEY = ON
--
-- Regular Index with "IGNORE_DUP_KEY = ON"
--
CREATE NONCLUSTERED INDEX UQ_Test_IGNORE_DUP_KEY_SSN
ON dbo.Test_IGNORE_DUP_KEY (SSN ASC)
WITH (IGNORE_DUP_KEY = ON)
GO
Obviously, this does not make sense. So, Sql Server throws the following error.
Msg 1916, Level 16, State 4, Line 1
CREATE INDEX options nonunique and ignore_dup_key are mutually exclusive.
In simple English, this setting is like saying. Don’t watch for duplicate records, but if you see them, do something (IGNORE).When you are not watching for duplicate records, we cannot ask for Sql Server to take some action.

IGNORE_DUP_KEY : Incorrect Setting
IGNORE_DUP_KEY = OFF
--
-- Regular Index with "IGNORE_DUP_KEY = OFF"
--
CREATE NONCLUSTERED INDEX UQ_Test_IGNORE_DUP_KEY_SSN
ON dbo.Test_IGNORE_DUP_KEY (SSN ASC)
WITH (IGNORE_DUP_KEY = OFF)
GO
Surprisingly this does not throw any error. One way to look at this is, “Don’t look for duplicate records, and there are no settings set to ON to watch for.” Since IGNORE_DUP_KEY=OFF, there is no setting to watch for or no overlay conditions on top on regular index. So, when a duplicate record is inserted, it is successfully inserted into the table.

IGNORE_DUP_KEY : No Affect
Summary
In summary, this is how these two settings work together.
When index is UNIQUE + IGNORE_DUP_KEY=ON
- Duplicate entries are ignored with an informational message (no error raised).
- Non-duplicate records are entered successfully.
- When mixed set is INSERTED, only informational message is displayed.
- Good records are inserted and duplicate are ignored.
When the index is UNIQUE + IGNORE_DUP_KEY=OFF
- Clear error message is displayed when duplicate entries inserted. Statement is terminated.
- Non-duplicate records are entered successfully.
- When mixed set is INSERTED, error message is displayed with and entire transaction is terminated
When the index is Non-UNIQUE + IGNORE_DUP_KEY=ON
When the index is Non-UNIQUE + IGNORE_DUP_KEY=OFF
- INSERT is successful with duplicate entries.
Flash Card Summary
|
IGNORE_DUP_KEY = ON |
IGNORE_DUP_KEY = OFF |
| UNIQUE Index |
Duplicates are ignored with informational message. |
Entire transaction is terminated with error message. |
| Non-Unique Index |
Setting not allowed. |
Duplicate entries are inserted successfully. |
Hope this helps,
_Sqltimes
Read Full Post »