Recently, during review of some T-SQL code, I ran into the usage of “not equal to (<>)” operator in one of the queries with LEFT OUTER JOIN. This is interesting, because the general perception of ‘not equal to’ is different from the way Sql Server processes it.
Let’s take an example:
Two tables, Table1 & Table2, with similar structure.
--
-- Create tables
--
CREATE TABLE dbo.Table1(
ID INT NOT NULL IDENTITY(1,1)
, PatientID INT NULL
, SomeCode VARCHAR(10) NULL
)
GO
CREATE TABLE dbo.Table2(
ID INT NOT NULL IDENTITY(1,1)
, PatientID INT NULL
, SomeCode VARCHAR(10) NULL
)
GO
--
-- Load dummy data
--
INSERT INTO dbo.Table1(PatientID, SomeCode)
VALUES (1, 'Code1')
, (1, 'Code2')
, (1, 'Code3')
, (2, 'Code1')
, (2, 'Code2')
, (3, 'Code1')
GO</pre>
<pre>
INSERT INTO dbo.Table2(PatientID, SomeCode)
VALUES (1, 'Code1')
, (1, 'Code2')
, (1, 'Code3')
, (2, 'Code1')
, (2, 'Code3')
, (2, 'Code4')
, (3, 'Code1')
GO
Here, in Table1, Patient No.1 has 3 codes i.e. Code1, 2, 3 & Patient 2 has 2 codes i.e Code1, 2; Patient3, etc
Requirement Definition
In plain English, if we say, we want to see all records from Table1, that do not have a matching record in Table1 (a.k.a. LEFT OUTER JOIN scenario).
You want to see something like this:

Dataset and manual comparision
The data set in green is the matching and red is the non-matching. So you only want to see the ones in red box (but only from Table1 – left hand side).
Options
This general English language query could be converted into these two SQL queries
--
-- Option 1: Using <> operator
--
SELECT A.PatientID, A.SomeCode, B.PatientID, B.SomeCode
FROM dbo.Table1 AS A
LEFT OUTER JOIN dbo.Table2 AS B
ON A.PatientID = B.PatientID
AND A.SomeCode <> B.SomeCode
GO
This results in more data than what we expect. For every record in Table1, it cartesian-join’s every record in Table2 (after PatientID condition) and return every combination of mis-match.
See the image below:

Not Equal Operator Output
--
-- Option 2: Using "WHERE SomeCode IS NULL"
--
SELECT A.PatientID, A.SomeCode, B.PatientID, B.SomeCode
FROM dbo.Table1 AS A
LEFT OUTER JOIN dbo.Table2 AS B
ON A.PatientID = B.PatientID
AND A.SomeCode = B.SomeCode
WHERE B.SomeCode IS NULL
GO
This returns the correct dataset that we are expecting i.e. only the records from Table1 that do not have matching record in Table2.
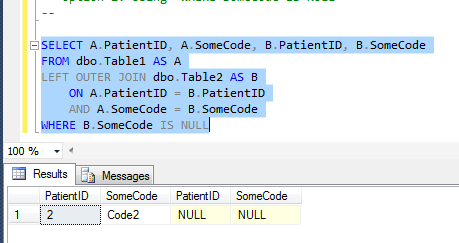
Using WHERE CLAUSE
Summary
In the first version, when we say ‘<>’ (A.SomeCode <> B.Somecode, though in plain English we seem to be asking the correct question, in SQL the meaning changes. This returns a lot more data than what we’d like to see.
It takes each record from Table1 and returns every record from Table2, that does not match it (after PatiendID condition is applied), like a cartesian join
In general terms, stay away from ‘<>’ operator, unless it is the exact logic you need. Also, it is inefficient for general use cases.
Hope this helps,
_Sqltimes

