Interesting topic today:
In Sql Server, as we all know, concurrency is maintained through locks & latches. When a particular row is being retrieved for any activity, a lock is requested on that row a.k.a. Shared lock or Exclusive lock, depending on the nature of the activity performed. Once activity is completed, the lock is released. So, when a large number of records in a table are retrieved, then something interesting happens. Sql Server, rather than issuing individuals locks on each row, it perform Lock Escalation to lock the entire table.
This behavior is helpful in some scenarios and detrimental in others. Each lock takes some resources (memory, etc). So establishing a large number of smaller locks (ROWLOCKs) aggregates to a lot of resources. So, Sql Server escalates the lock to either PAGE level or TABLE level (depending on the scenario). Sometimes this could result in longer waits for the PAGE (or entire table) to be freed from other locks, before this new lock request could be granted.
To avoid all of this, sometimes, developers use ROWLOCK to force Sql Server to use ROWLOCK even when performing operations on larger number of records (to avoid waiting for entire PAGE/TABLE to be free from other locks). There are several pros and cons to this approach. As always, the details of the situation guide the best approach in each scenario. One exception to this scenario is, even though we use ROWLOCK, sometimes Sql Server will force lock escalation.
Today, we’ll look at this one aspect of this automatic lock escalation:
Question: At what point does Sql Server, force lock escalation even when ROWLOCK is used?
Let’s run DELETE on a table and see how lock escalation happens. Three diferent levels:
- 2000 ROWLOCK requests
- 4000 ROWLOCK requests
- 6000 ROWLOCK requests
Step 1: At 2000 ROWLOCKS
--
-- Let's run a large DELETE operation
--
DELETE TOP (2000) FROM dbo.SampleTable WITH (ROWLOCK) GO
Now, in a different SSMS window, let’s check the number of locks on the table.
--
-- Check locks on the table
--
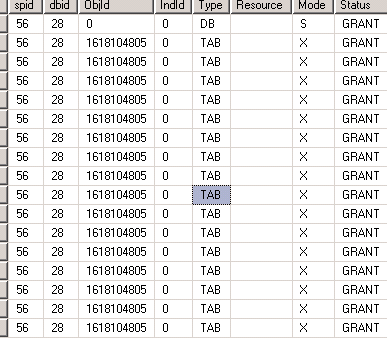
EXEC sp_lock 56
WAITFOR DELAY '00:00:01' -- keep running every second, to capture locks from other window
GO 10

Row Level Locks Granted
As you can see ROWLOCKS on keys are GRANTed. Now, lets increase the batch size and see where the force lock escalation happens.
Step 2: At 4000 ROWLOCKS
--
-- Let's run a large DELETE operation
--
DELETE TOP (4000)
FROM dbo.SampleTable WITH (ROWLOCK)
GO
Let’s check the lock situation:

ROWLOCKs granted at 4000
So, even at 4000, something interesting happens. Some ROWLOCKs are issues and some PAGELOCKS are issued. Looks like for some rows, the lock is escalated to the PAGELOCK level for efficiency. Let’ continue the effort
Step 3: At 6000 ROWLOCKS
--
-- Let's run a large DELETE operation
--
DELETE TOP (6000)
FROM dbo.SampleTable WITH (ROWLOCK)
GO
Let’s review the locks situation:

ROWLOCKs at 6000
BINGO !!! As you can see the lock escalation occurs to TABLOCK level at 6000.
Initially, ROWLOCKS are issued; Then just a second later, some locks are escalated to PAGE and subsequently to TABLE level. This is interesting.
Another Nuance: Percentage
Question: Does this escalation occur based on a strict number (or range) or is it based on percentage of records being accessed in a table?
- From the tests, it seems like the LOCK ESCALATION occurs based on the number, and not percentage of records being manipulated.
| Table Size |
Total Record Count |
Count of records Lock Requested |
Type of Lock Granted |
| Small |
2,100 |
2000 |
ROWLOCK |
| Medium |
35,000 |
2000 |
ROWLOCK |
| Large |
500,000 |
2000 |
ROWLOCK |
Conclusion:
- Sql Server makes intelligent estimations on what is better at each level and makes best decisions to escalate locks as needed. Keep the 2000, 4000 & 6000 as general rule in mind and not as a set in stone rule.
- At any given point, Sql Server makes the best judgement call on what is more efficient.
- Lock Escalation is based on the number of records on which lock is requested and not on the percentage of records relative to the total records in the table.
Important Note:
- This behavior applies only to Sql Server 2012 as this behavior varies from version to version.
- In the past, for Sql Server 2008 and before, the number was at 1800 – 2200 before TABLE lock escalation occurs.
- If this continues, may be for Sql Server 2016, the number would be slightly higher, as Microsoft improves the lock efficiency by reducing the amount f resources required for each lock.
- This does not mean to go ‘free range’ crazy and use ROWLOCK on every query (obviously) & use 4000 everytime. Keep this information handy in making data retrieval decisions. Each ROWLOCK takes resources (memory & CPU); So we need to use caution and minimize the overhead. This a refined technique to be used in infrequent occassions that seem the most suitable for such techniques. Perfom tests before using in production.
Read Full Post »