Quick one today:
Very often, this comes up in regular conversations. What is the difference between COUNT(*) & COUNT(1)?
Short Answer
No difference; They perform the same and give the same result. Internally they work almost the same way too.
Details
Lets look at some artifacts:
-- -- Capture execution plans between both the styles -- SET STATISTICS IO ON SET STATISTICS TIME ON SELECT COUNT(*) FROM dbo.Numbers GO SELECT COUNT(1) FROM dbo.Numbers GO SET STATISTICS IO OFF SET STATISTICS TIME ON GO
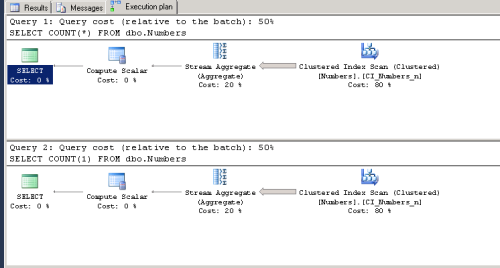
Execution Plans:
The plans look exactly the same, including the details of each step a.k.a. Operator Cost, Physical Operation, Subtree Cost, etc.
I/O Metrics
As you can see, the logical & physical I/O on both the queries is exactly the same.
-- COUNT(*)
Table 'Numbers'.
Scan count 1,
logical reads 1703,
physical reads 0,
read-ahead reads 0,
lob logical reads 0,
lob physical reads 0,
lob read-ahead reads 0.
-- for COUNT(1)
Table 'Numbers'.
Scan count 1,
logical reads 1703,
physical reads 0,
read-ahead reads 0,
lob logical reads 0,
lob physical reads 0,
lob read-ahead reads 0.
CPU Artifacts
CPU consumption has a slight variation. COUNT(*) uses a few more CPU cycles than COUNT(1). Is this significant? Not really.
--For COUNT(*) SQL Server Execution Times: CPU time = 187 ms, elapsed time = 197 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. -- For COUNT(1) SQL Server Execution Times: CPU time = 171 ms, elapsed time = 176 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms.
Important point to note here is the order in which you run them. Which ever is run first, that performs physical I/O, that the subsequent COUNT query does not need to do. Other than that, they seem very similar in performance.
Important Point: Even when I ran these queries on a very large table, they performed exactly with the same performance metrics. The CPU difference was negligible (only 4 milliseconds).
Note: If you are running counts on larger tables, use COUNT_BIG(*).
_Sqltimes
